У большинства команд мониторинг, алерты, дежурства и внешняя коммуникация живут в разных сервисах. В результате сигнал приходит в одном окне, инцидент ведется в другом, дежурный ищется в третьем, а клиентам статус обновляют вручную.
Чем больше таких разрывов, тем выше время реакции, больше операционный шум и выше риск пропустить критичную проблему.
По данным исследования рынка специалистов по надёжности в России, только половина команд формализовала процесс реагирования на инциденты, а автоматическая маршрутизация есть примерно у трети организаций. При этом одна из главных проблем — нехватка времени на повышение стабильности сервисов
ict.moscow.
Слишком много ручных действий
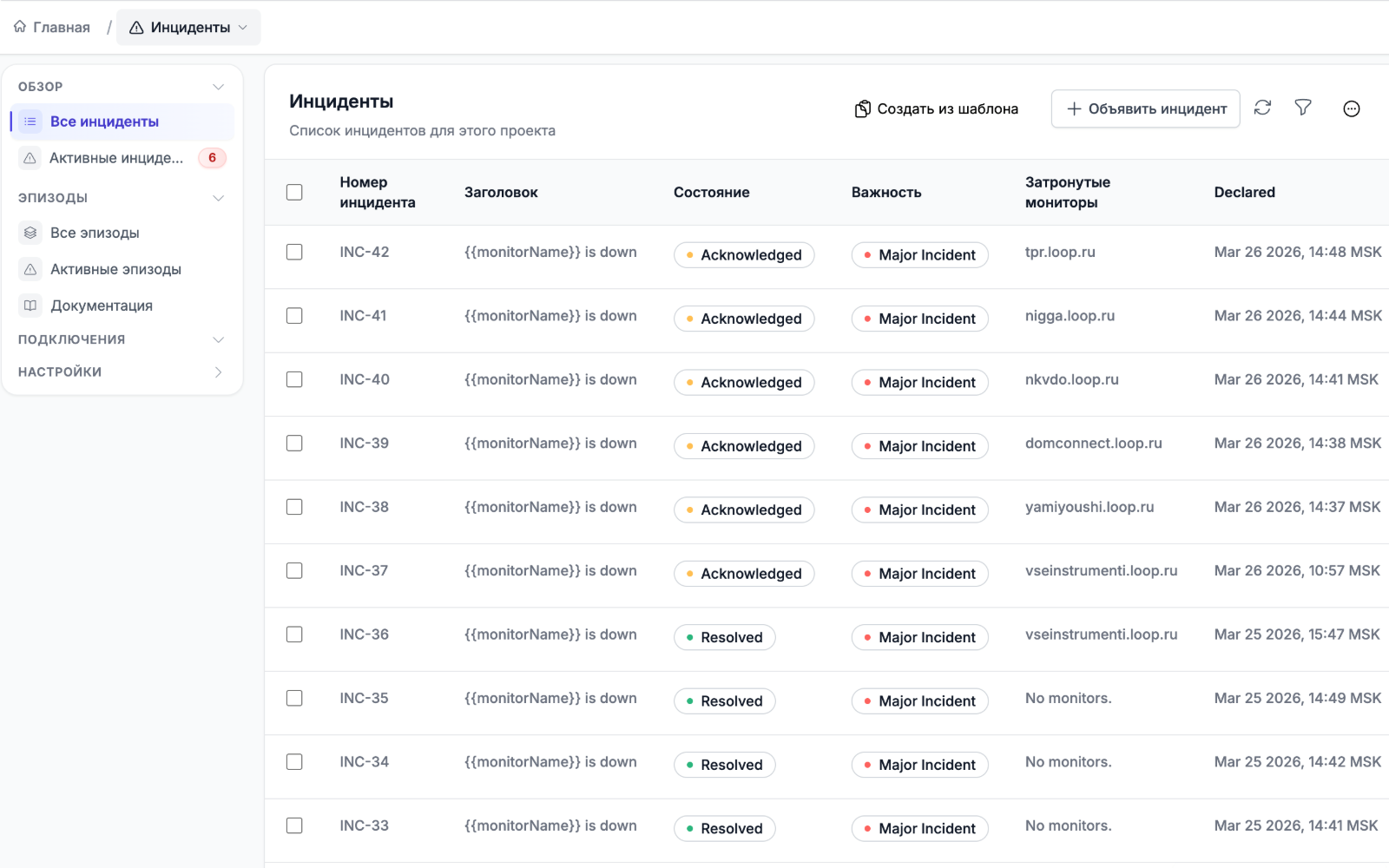
Мониторинг заметил проблему, но дальше всё зависит от того, кто увидел сигнал, кому написал и кто обновил статус вручную.
Нет ясного ответственного за инцидент
Сигнал есть, а ответственности и понятного сценария реагирования нет.
Зоопарк инструментов
Одна команда поддерживает несколько сервисов, интеграций, правил, пользователей и каналов уведомлений.
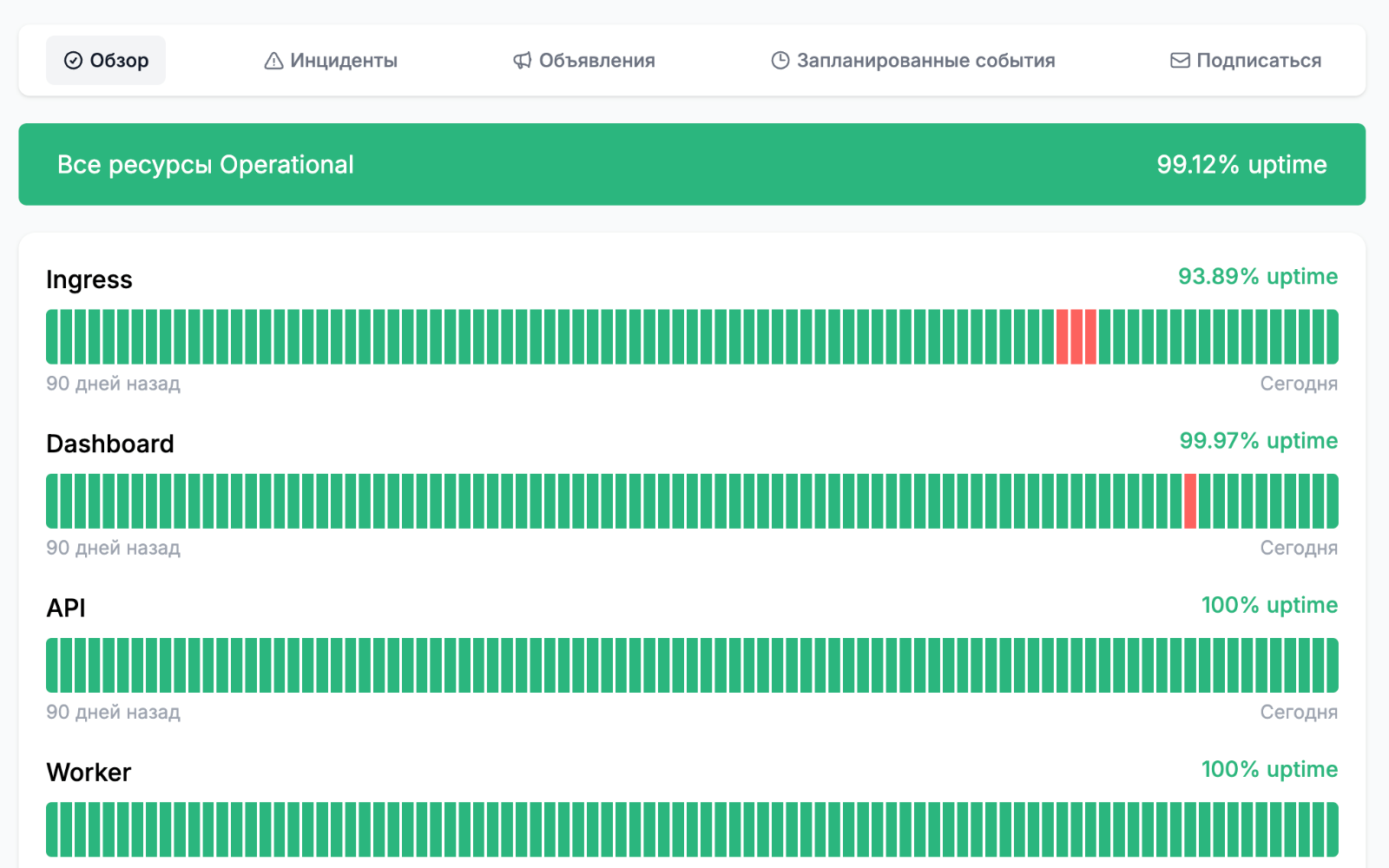
Клиенты узнают о сбое раньше команды
Если статус-страница и коммуникация не встроены в процесс реагирования, доверие теряется быстрее, чем восстанавливается сервис.